When I was a kid, I played basketball at about the level you’d expect a not athletic future engineer to play - poorly and awkwardly. In our first game, my coach asked me to stay under our basket and wait for the ball, which I did. When the other team had the ball, I waited carefully on the other side of the court by our basket, confused why everyone was yelling at me to leave my post. I was promptly removed from the game.
This is what training a reinforcement learning agent feels like sometimes. If you aren’t careful with how you specify the problem, your agent might take you too literally and learn the “wrong” thing.
There’s even a thought experiment called the paperclip maximizer which describes how an AI designed to make paperclips could kill all humans. While we are hopefully a long way away from being murdered by paper clip robots, today I’d like to demonstrate the effect that small changes to our reward functions could have on our agents’ strategies.
First, we’ll need a reinforcement learning environment that’s simple enough that we can easily understand our agents’ strategies, but complicated enough that there isn’t one obvious perfect strategy. If you aren’t sure what a reinforcement learning environment is, check out my last post which goes through a simple example.
The Auto-Scaling Environment
We will simulate building a web application that responds to HTTP requests. We will have a lot of requests, so we need to split the load across different servers. Our agent is responsible for managing a cluster of servers to best respond to the requests. The word best in the last sentence is intentionally ambiguous. Our agent will learn what “best” means by the rewards we give it.
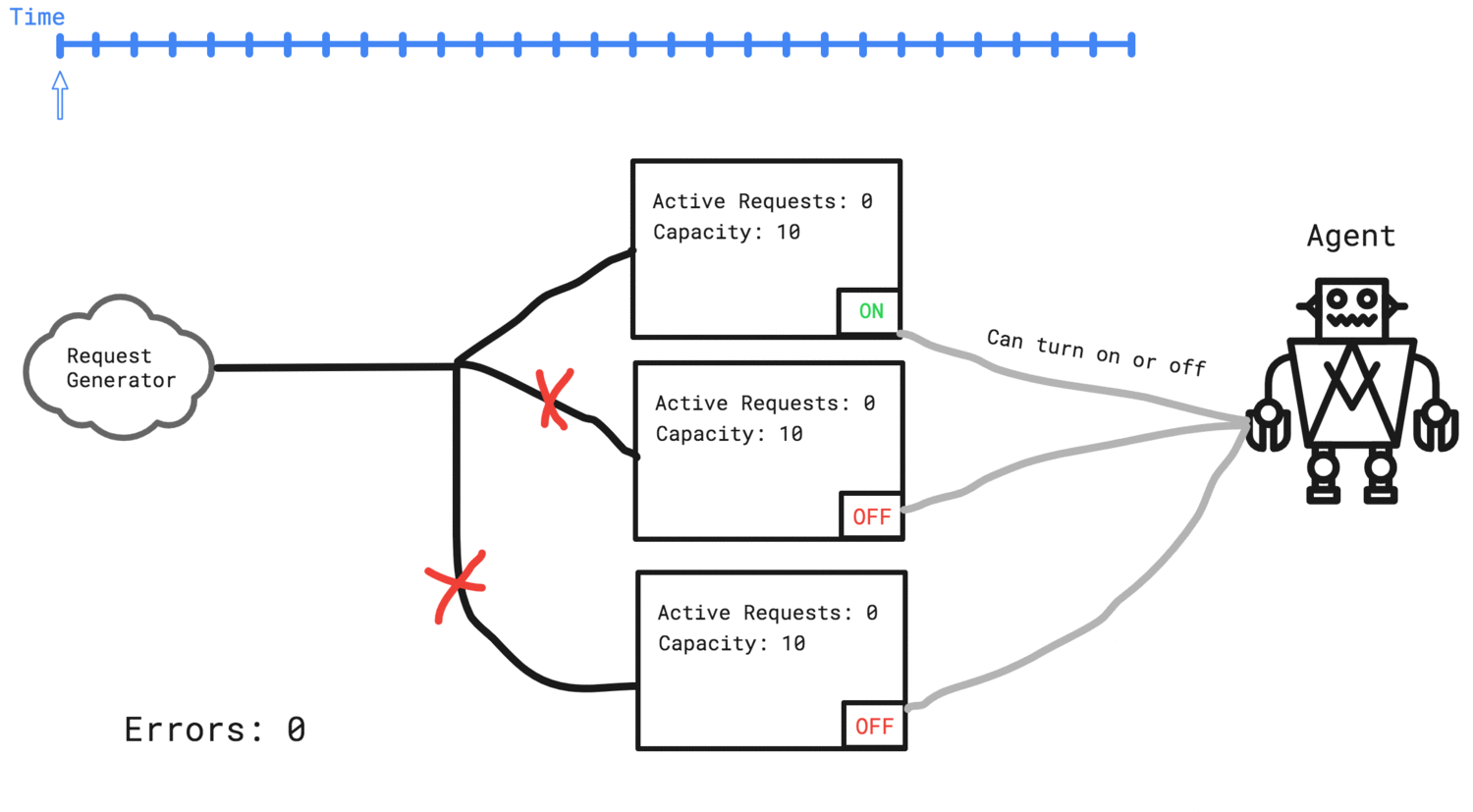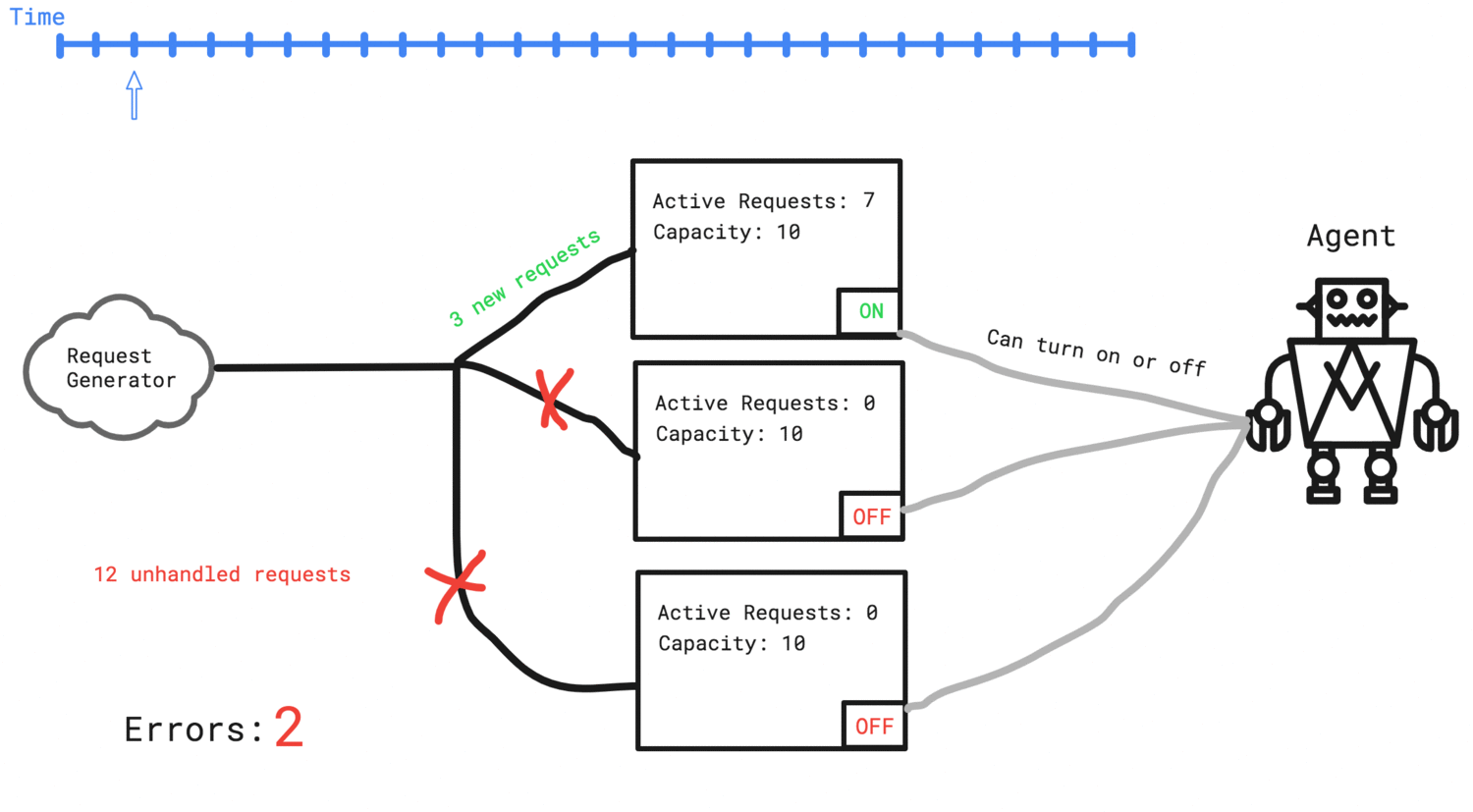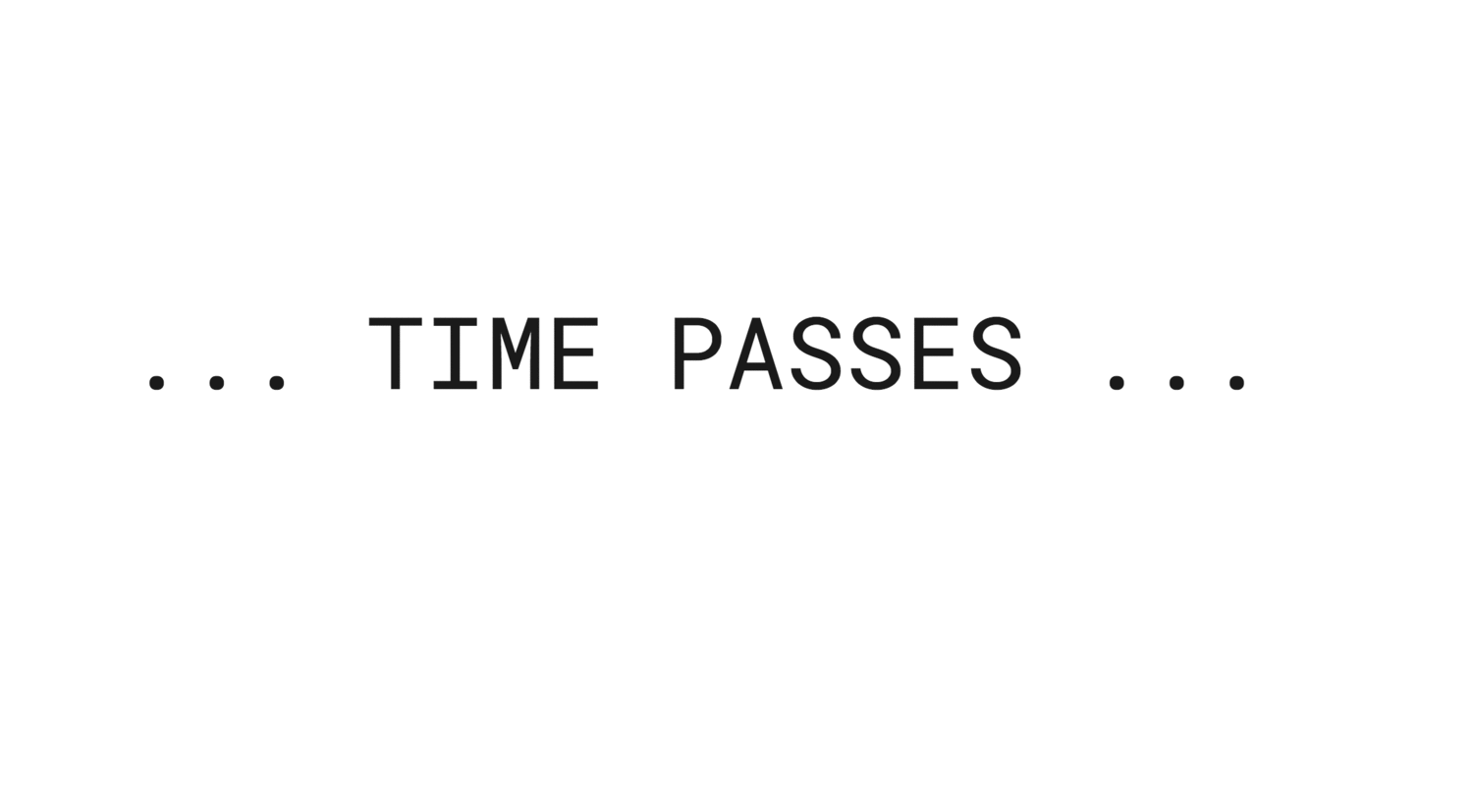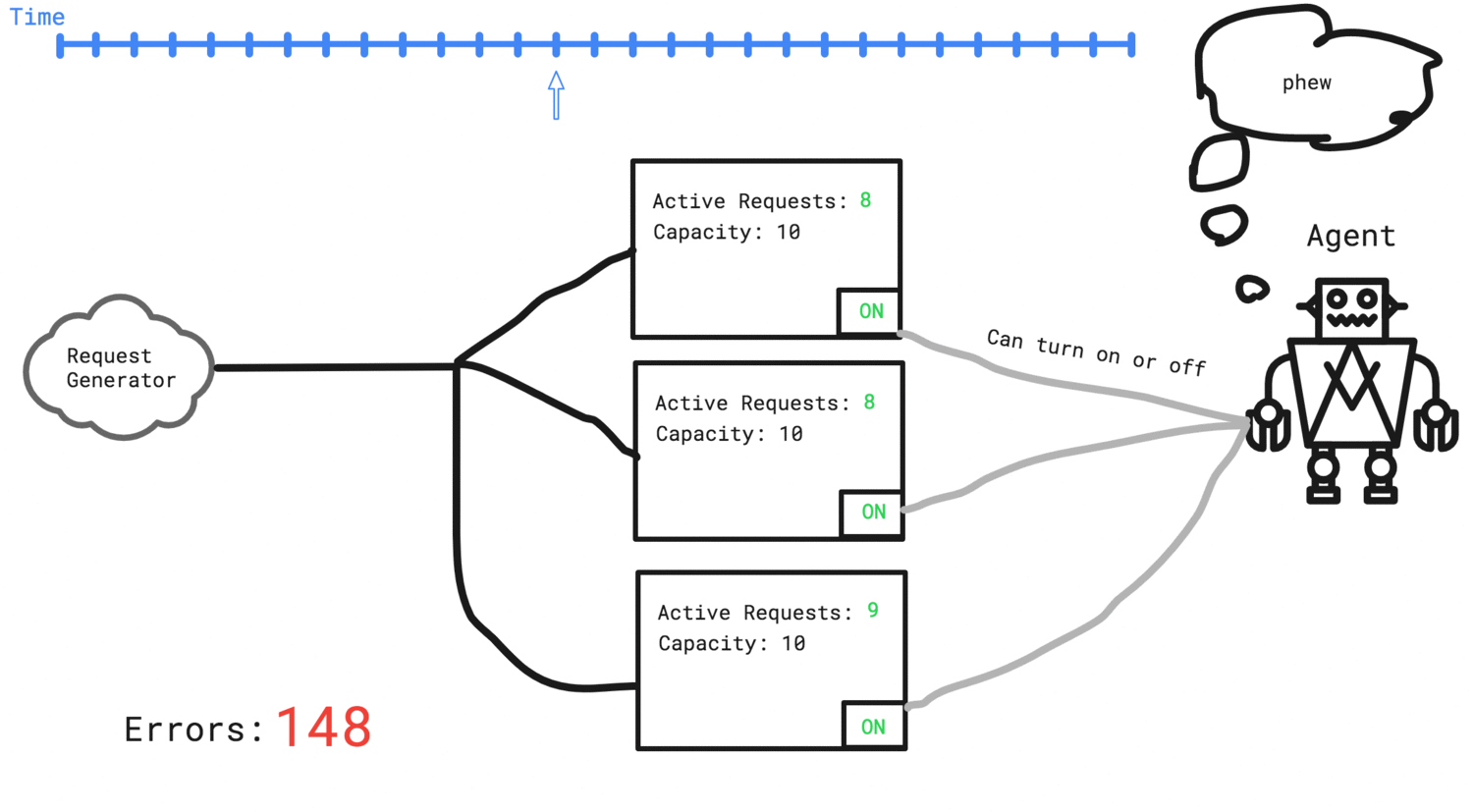
The agent needs to add two more servers to the cluster in order to handle the traffic
In more detail:
- Our agent is responsible for starting/stopping servers to handle these requests.
- The rate of requests that we get changes throughout the day, so we’ll have some periods where we frequently get requests and other periods where we rarely get requests.
- Each request has a variable amount of time that it takes the server to process.
- Each server has a capacity, and if a request comes in when we have no capacity left on any of our servers, we consider that an error and the request fails.
- Requests are automatically sent to the server that’s currently handling the fewest requests.
- Turning a server on is not instantaneous, it takes a variable amount of time.
- Turning a server off will immediately stop it from receiving future requests, and it will fully die when all active requests have completed.
We’re also not trying to build a real-life auto-scaler, this is more of a demonstration, so we’re going to make some additional simplifying assumptions:
- We will use a discrete time space and multiple requests will appear to happen at the same exact time.
- Servers can never fail or degrade in performance when they get busy. The only time a server dies is when our agent asks it to turn off.
- Each request takes up 1 “unit of space” on a server. A server’s capacity is just an upper bound on the number of active requests it can have at any point in time.
- Requests are not retried or put in a queue to wait. Once they fail, they count as an error and are gone forever.
If you don’t like the server/request abstraction, you can also think of this as deciding how many waiters/waitresses you need in a restaurant. Each waiter/waitress can only take care of so many people, and if you have too few, people coming to your restaurant (requests) will need to be rejected.
Since there are a lot of pieces that we need to build, this project will be split into the following parts:
- Introducing the problem (this post)
- Simulating HTTP traffic
- Simulating a cluster of servers
- Feature engineering for our auto-scaling environment
- How reward functions affect our agents’ decisions
If you aren’t interested in the details/code of the environment, feel free to skip to the last post which focuses only on the impact our reward function has on our agent’s strategies. Otherwise, I’ll see you in the next post where we will simulate realistic HTTP traffic for our auto-scaling environment.