This post is part of a series. If you haven’t read the introduction yet, you might want to go back and read it so you can understand why we are doing this.
Modeling random request volumes and durations
The first piece of our environment that we will tackle is simulating HTTP traffic. We will assume that the rate of HTTP requests varies throughout the day, but has some peak time periods and some slow time periods. We will also assume that requests need to vary in the duration they take to be processed. Some requests will be way more expensive than others.
To simulate the rate of requests, at each timestep, we’ll flip N coins that have some probability p of being heads. For every heads we see, we’ll generate a request, and we’ll ignore all tails. We can then control the rough amount of requests by modifying the probability p. The higher the probability, the more heads, the more requests. Let’s now generate the probability function that varies throughout the day, and to do this, I started from this stackoverflow post and modified it until I thought the graph seemed reasonable.
import math
import matplotlib.pyplot as plt
MAX_TIME = 2000
def cos(t):
return (math.cos(3 * math.pi * t / MAX_TIME + 1.5) + 1) / 2
def sin(t):
return (math.sin(3 * math.pi * t / MAX_TIME - 1.5) + 1) / 2
def get_probability(t):
# Skip the first 100 timesteps to give the agent some time to get set up
if t < 100:
return 0
x = 0.4 * sin(t) + 0.45 * cos(2 * t) + 0.15 * cos(t / 2) + sin(t * 3)
return 1 - math.exp(-x)
plt.xlabel("time")
plt.ylabel("probability of a request")
plt.plot([get_probability(t) for t in range(MAX_TIME)])
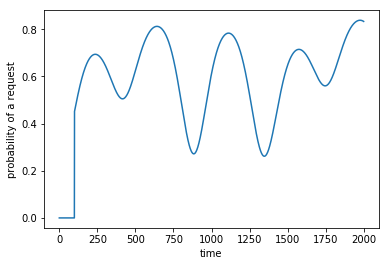
Now let’s generate the requests using the variable probability. If we create a histogram of the times that the requests happen, it should look like the probability vs time curve.
import random
import numpy as np
def flip_coin(prob):
return random.random() <= prob
def generate_request_times(max_requests_per_timestep):
request_times = []
for time in range(MAX_TIME):
for _ in range(max_requests_per_timestep):
prob = get_probability(time)
if flip_coin(prob):
request_times.append(time)
return np.array(request_times)
request_times = generate_request_times(50)
plt.title("Requests bucketed into large buckets (40)")
plt.xlabel("time")
plt.ylabel("num requests")
plt.hist(request_times, bins=range(0, MAX_TIME, 40))
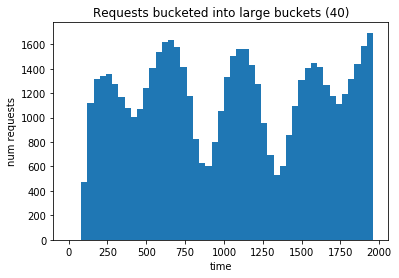
And it does, but if we create a histogram with a much smaller bucket size we can see that there is still a decent amount of variability from timestep to timestep, which is exactly what we want. Our agent should learn how to figure out the overall trend from the noise.
plt.title("Requests bucketed into small buckets (4)")
plt.xlabel("time")
plt.ylabel("num requests")
plt.hist(request_times, bins=range(0, MAX_TIME, 4))
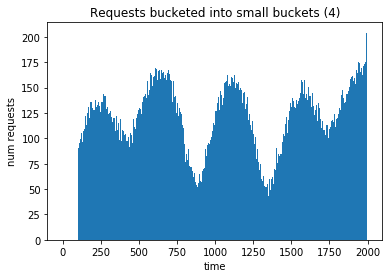
Great! Now we need some durations. This is a lot simpler because we can just sample from a lognormal distribution for each request to get its duration. Here’s the code and a histogram which I tweaked until it looked reasonable:
def generate_request_durations(size):
return np.random.lognormal(0, 0.5, (size, )) * 2 + 1
request_durations = generate_request_durations(MAX_TIME)
plt.title("Request duration histogram")
plt.ylabel("number of requests")
plt.xlabel("request duration")
plt.hist(request_durations, bins=np.arange(0, 20, 0.1))
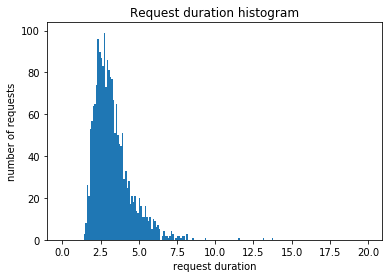
Most requests take about the same amount of time, but there is still a long tail of requests that take way longer than any of the other ones.
Bringing it all together
Ultimately, it would be nice to have a class that generates “requests” for us, where a request should have both a timestamp and a duration. Given the functions that we’ve already defined, this is pretty straightforward:
class Request:
def __init__(self, time, duration):
self.time = time
self.duration = duration
class RequestGenerator:
def __init__(self, max_requests_per_timestep):
self.max_requests_per_timestep = max_requests_per_timestep
def generate(self):
request_times = generate_request_times(self.max_requests_per_timestep)
request_times.sort()
request_durations = generate_request_durations(len(request_times))
request_durations = request_durations.astype('int32')
requests = []
for time, duration in zip(request_times, request_durations):
requests.append(Request(time, duration))
return requests
If you print out some examples, you’ll see this generates requests at different times with different durations based on the work we did above. You can also control the volume of requests with max_requests_per_timestamp. Note that it starts at 100 because our probability function is 0 until time 100 to give the agent time to prepare.
> list(map(lambda r: r.__dict__, RequestGenerator(5).generate()))
[{'duration': 4, 'time': 100},
{'duration': 4, 'time': 100},
{'duration': 6, 'time': 100},
{'duration': 2, 'time': 101},
{'duration': 3, 'time': 101},
{'duration': 2, 'time': 102},
{'duration': 1, 'time': 102},
{'duration': 1, 'time': 103},
...
Ultimately, we’ll use this in our environment. We can call it when our environment is resetting and generate all the traffic for a single episode.
In my next post, we’ll build a simulation of a cluster of servers to process these requests.