This post is part of a series. If you haven’t read the introduction yet, you might want to go back and read it so you can understand why we are doing this.
Feature engineering
So far, we’ve decided that our agent, at each timestep, can choose from one of three options:
- Add a new server to our cluster (up to a limit)
- Remove a server from our cluster (once all the requests that server is handling are done)
- Do nothing
And we’ve built out all the necessary tools for simulating both our stream of requests and our cluster responsible for handling those requests. However, our agent needs some information in order to pick the “best” action, or in other words, we need to decide what the observation space is.
The information that we give to our agent is generally referred to as features and the process of picking those features is referred to as feature engineering.
One exercise I like to do is to put myself in the agents’ shoes. Imagine you were tasked with manually scaling a cluster. What features do you think you would need to make the best decision possible?
Brainstorming a few ideas:
- How many servers are currently on/accepting requests?
- What is the capacity of each server?
- How many requests is each server handling currently?
- How many requests have we received over the last few time steps? Is it increasing or decreasing?
- ⚠️ How long will it take a server to start up or shut down?
- ⚠️ How many requests are we about to receive?
I marked two of the ideas with a danger symbol (⚠️), can you guess why?
Ultimately, everything we are doing here is to simulate what it would be like if our agent was controlling a cluster of servers. The simulation allows our agent to try out many strategies without literally spinning up real servers and costing us real money. Simulating also comes with an advantage that we can speed up time and get lots of experience in a really short wall clock time period.
However, for our agent to be useful (other than for just a blog post), it eventually needs to control a real cluster of servers - in real time. Things like “How many requests are we about to receive” are technically available to us in our environment, but in the real world, we won’t have that information.
The other features all seem reasonable, so let’s create a new class that will produce these features:
# Divide function where 0/0 = 0
def safe_divide(a, b):
if a == 0:
return 0
else:
return a / b
class FeatureExtractor:
def __init__(self, cluster, max_num_requests):
self.cluster = cluster
self.max_num_requests = max_num_requests
self.prev_time_requests = 0
def get_features(self):
features = []
for server in self.cluster.get_servers():
features.extend([
1.0 if server.is_on() else 0.0,
1.0 if server.is_accepting_requests() else 0.0,
1.0 if server.is_transitioning() else 0.0,
server.get_free_space() / server.capacity,
])
# TODO: how do we handle historical features?
# Be extra cautious in case max_num_requests is 0
features.append(safe_divide(self.prev_time_requests,
self.max_num_requests))
return features
def record_new_requests(self, new_request_count):
self.prev_time_requests = new_request_count
def get_num_features(self):
return 4 * self.cluster.get_max_num_servers() + 1
This ultimately produces four features per server and one overall feature about traffic. I combined the free space and capacity features together to get a value between 0 and 1 which represents how much space is left over relative to the overall capacity of the server. I also normalized the number of requests by dividing by the maximum that we can receive in a single time step.
What about historical features?
As the TODO calls out, only giving our agent the previous timestep’s traffic may not be enough information. In the second post, we saw that from timestep to timestep, the traffic is a little noisy, but as you average together more points in time, you can start to make out the overall trend.
One way to add in historical features is to have record_new_requests store the last N request counts. If N is 10, then this would be the equivalent of saying “I have 4 features per server, and 10 extra features representing the last 10 traffic amounts I saw”. This approach is great if you only have one or two features that you care about having historical information on, however, if we wanted to also have historical information on is_transitioning (which seems like a good idea so we can anticipate roughly when a new server will be available), we’d need to also start storing lists of the last couple of is_transitioning values.
Another way to add in historical features is to allow our agent to remember past values of all our features by using a policy with a recurrent neural network such as stable-baselines MlpLstmPolicy. Without going into too much detail, these types of policies can figure out what information is important to remember and what information can be forgotten over time, but they will take longer to train than the first approach.
A third way (and the one we will go with) is to use a FrameStack. This technique wraps your entire environment and instead of returning just a single observation, it will automatically stack the last N (you choose N) observations together for you. This is essentially the same as the first approach we talked about, but FrameStack will take care of storing the last few observations, and it will work automatically for all of your features. It’s a nice balance between keeping our policy simple and not writing a lot more code. This means that we can just remove the TODO and we are good to go.
It’s also important to realize that your agent cannot see anything past N observations. So if you set N=4, your bot cannot know that a server has been turning off for 6 timestep. It can only know that it was turning off for 0, 1, 2, 3, or at least 4 timesteps.
Environment
Almost all the pieces of the puzzle are there. We can generate requests, we can handle those requests, and we can extract features from our environment. My next post will deal with our reward function, but for now, we can put it all together in an environment:
from gym import spaces
import gym
ACTION_REMOVE_SERVER = 0
ACTION_DO_NOTHING = 1
ACTION_ADD_SERVER = 2
class AutoScalingEnv(gym.Env):
def __init__(self, cluster, request_generator, feature_extractor, reward_fn):
'''
cluster: responsible for managing our servers
request_generator: called on reset and generates ALL the
requests we will ever receive, including the times they
occur and durations
feature_extractor: produces information for our agent to observe
reward_fn: calculates rewards for our agent
'''
self.cluster = cluster
self.request_generator = request_generator
self.feature_extractor = feature_extractor
self.reward_fn = reward_fn
# 0 => remove a server, 1 => do nothing, 2 => add a server
self.action_space = spaces.Discrete(3)
# We will use frame stacking to add historical information in,
# but frame stacking only works with a 3d feature space,
# so we'll just hack in 2 dimensions
self.obs_shape = (
feature_extractor.get_num_features(),
1,
1,
)
self.observation_space = spaces.Box(0, 1, shape=self.obs_shape)
self.reset()
def reset(self):
self.pending_requests = self.request_generator.generate()
self.cluster.reset()
self.feature_extractor.record_new_requests(0)
self.current_time = 0
self.done = False
# last errors will be useful for our reward functions
self.last_errors = 0
self.errors = 0
return self._get_observation()
def step(self, action):
if self.done:
raise Exception('Time literally ran out')
# Let the agent's action come before the requests
self._handle_action(action)
self._process_time()
self._process_new_requests()
reward = self.compute_reward()
obs = self._get_observation()
info = self._get_info()
return obs, reward, self.done, info
def _handle_action(self, action):
if action == ACTION_REMOVE_SERVER:
self.cluster.remove_server()
elif action == ACTION_ADD_SERVER:
self.cluster.add_server()
def _process_time(self):
self.current_time += 1
self.cluster.advance_time()
def _process_new_requests(self):
if len(self.pending_requests) == 0:
self.done = True
return
idx = self._get_index_of_last_new_request()
# Our feature extractor needs the rate of requests
# The next observation will contain the current request count
new_request_count = idx + 1
self.feature_extractor.record_new_requests(new_request_count)
if idx < 0:
return
new_requests = self.pending_requests[0:(idx + 1)]
self.pending_requests = self.pending_requests[(idx + 1):]
new_errors = self.cluster.handle_new_requests(new_requests)
self.errors += new_errors
# Returns -1 if there are no new requests
def _get_index_of_last_new_request(self):
idx = -1
for i, pending_request in enumerate(self.pending_requests):
if pending_request.time <= self.current_time:
idx = i
else:
break
return idx
def compute_reward(self):
reward = self.reward_fn(self.errors, self.last_errors, self.cluster)
self.last_errors = self.errors
return reward
def _get_observation(self):
features = self.feature_extractor.get_features()
features = np.array(features)
return features.reshape((-1, 1, 1))
# Will be useful for debugging
def _get_info(self):
num_servers_on = 0
active_requests = 0
for server in self.cluster.get_servers():
if server.is_on():
num_servers_on += 1
active_requests += len(server.active_request_durations)
return {
'num_servers_on': num_servers_on,
'error_count': self.errors,
'total_requests_active': active_requests,
}
def render(self, mode='human', close=False):
pass
def seed(self, seed):
random.seed(seed)
I didn’t implement the render function because I think it’s easier to visualize the entire stream of time at once instead of a single frame at a time. We’ll address that in a second, but first, we need an example agent to visualize.
Training our first agent
We’re using stable-baselines which will make it really easy to train an agent on our environment. To speed things up a little, we can follow this example to see how to parallelize our code by creating multiple environments to learn from at once.
Now all we need to do is construct all our classes and wire them together:
from stable_baselines.common.policies import MlpPolicy
from stable_baselines.common.vec_env import SubprocVecEnv, DummyVecEnv
from stable_baselines.common.atari_wrappers import FrameStack
from stable_baselines.common import set_global_seeds
MAX_NUM_SERVERS = 20
SERVER_CAPACITY = 10
MAX_REQUESTS_PER_TIMESTEP = 30
FRAME_STACK_SIZE = 8
NUM_PROCESSES = 8
def make_single_env(reward_fn, rank=0, use_directly=False):
def _init():
cluster = Cluster(
max_num_servers = MAX_NUM_SERVERS,
server_capacity = SERVER_CAPACITY
)
request_generator = RequestGenerator(MAX_REQUESTS_PER_TIMESTEP)
feature_extractor = FeatureExtractor(cluster, MAX_REQUESTS_PER_TIMESTEP)
env = AutoScalingEnv(cluster, request_generator, feature_extractor, reward_fn)
env.seed(rank)
env = FrameStack(env, FRAME_STACK_SIZE)
return env
set_global_seeds(0)
# If we want to directly use it, we'll need to wrap it in a DummyVecEnv
# but if we are using it in a multi process env, we don't want to wrap it
if use_directly:
return DummyVecEnv([_init])
else:
return _init
def make_multi_process_env(reward_fn):
envs = []
for rank in range(NUM_PROCESSES):
envs.append(make_single_env(reward_fn = reward_fn, rank = rank))
return SubprocVecEnv(envs)
The values I choose are just to test this end to end. Note that when we are training an agent, we’ll want to use the multi-process environment, but when we are visualizing our environment, it will be easier to use a single process environment.
We can quickly train an RL agent using PPO. We’ll specify a reward function just for testing, and we’ll use an MlpPolicy because our data is tabular. You can tune the parameters if you want, but the defaults will work fine here.
from stable_baselines import PPO2
def reward_fn(errors, last_errors, cluster):
# TODO
return 0
env = make_multi_process_env(reward_fn=reward_fn)
model = PPO2(MlpPolicy, env, verbose=0)
model.learn(total_timesteps=1000)
Visualizing our agents’ strategies
And finally, we need some way to see what the agent is actually doing. We can modify this matplotlib example to visualize three variables vs time (probability of a request, number of errors so far, number of servers currently on).
from mpl_toolkits.axes_grid1 import host_subplot
import mpl_toolkits.axisartist as AA
def play_game(env):
obs = env.reset()
errors = []
num_servers_on = []
while True:
action, _states = model.predict(obs)
obs, rewards, dones, infos = env.step(action)
errors.append(infos[0]['error_count'])
num_servers_on.append(infos[0]['num_servers_on'])
if dones[0]:
break
return (errors, num_servers_on)
def display_strategy(env):
errors, num_servers_on = play_game(env)
request_probability = [get_probability(t) for t in range(MAX_TIME)]
host = host_subplot(111, axes_class=AA.Axes)
plt.subplots_adjust(right=0.75)
errors_x = host.twinx()
num_servers_on_x = host.twinx()
offset = 60
new_fixed_axis = num_servers_on_x.get_grid_helper().new_fixed_axis
num_servers_on_x.axis["right"] = new_fixed_axis(
loc="right",
axes=num_servers_on_x,
offset=(offset, 0)
)
num_servers_on_x.axis["right"].toggle(all=True)
errors_x.axis["right"].toggle(all=True)
host.set_xlim(0, MAX_TIME)
host.set_ylim(0, 1)
host.set_xlabel("time")
host.set_ylabel("request_probability")
errors_x.set_ylabel("errors")
num_servers_on_x.set_ylabel("num_servers_on")
p1, = host.plot(request_probability, label="request_probability")
p2, = errors_x.plot(errors, label="errors")
p3, = num_servers_on_x.plot(num_servers_on, label="num_servers_on")
errors_x.set_ylim(-0.3, max(100, max(errors)))
num_servers_on_x.set_ylim(-0.3, 20.3)
host.axis["left"].label.set_color(p1.get_color())
errors_x.axis["right"].label.set_color(p2.get_color())
num_servers_on_x.axis["right"].label.set_color(p3.get_color())
plt.draw()
plt.show()
display_strategy(make_single_env(reward_fn, wrap=True))
Without a real reward function, the agents’ actions are basically random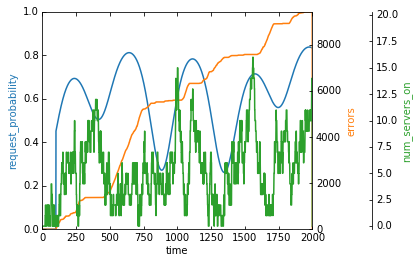
Looking at the above strategy, you should see that the error rate increases fastest when the probability of a request is high and the number of servers is low. You can also see points around 1500 where the error rate flattens out because the agent turns on a lot of servers in our cluster.
In my next post, we’ll look at defining a proper reward function and seeing how changes to that reward function will change the agents’ overall strategies.