This post is part of a series. If you haven’t read the introduction yet, you might want to go back and read it so you can understand why we are doing this.
So far, we’ve created an environment that simulates a cluster attempting to handle HTTP requests that come in varying volumes throughout the day. Our agent is responsible for adding and removing servers from our cluster to handle the traffic. We have not yet defined our reward function, and without a reward function, our agent doesn’t know what to do.
“Capacity planning”
We should know what to expect before our agent does anything. We picked pretty random values for our cluster size and traffic amounts, so we need to check some basic things first like “if our cluster was at its max size, can it handle peak traffic?” and “how many servers do we expect our cluster to use at peak vs at low traffic?”.
To do this, I’m going to create a cluster that has a single server with a really high capacity, turn the server on, and observe the traffic amounts. You can also probably use math to figure this out, but this is harder to mess up.
# Proposed parameters
MAX_NUM_SERVERS = 20
SERVER_CAPACITY = 10
MAX_REQUESTS_PER_TIMESTEP = 30
# how many timesteps back the agent can see
FRAME_STACK_SIZE = 8
NUM_PROCESSES = 8
def get_total_requests_active_over_single_run():
# ignoring the clusters' proposed parameters for this test
cluster = Cluster(max_num_servers=1, server_capacity=10000000)
request_generator = RequestGenerator(MAX_REQUESTS_PER_TIMESTEP)
feature_extractor = FeatureExtractor(cluster, MAX_REQUESTS_PER_TIMESTEP)
reward_fn = lambda x, y, z: 0
env = AutoScalingEnv(cluster, request_generator, feature_extractor, reward_fn)
env = DummyVecEnv([lambda: env])
env.reset()
total_requests_active = []
_, _, dones, infos = env.step([ACTION_ADD_SERVER])
done, info = dones[0], infos[0]
total_requests_active.append(info['total_requests_active'])
while not done:
_, _, dones, infos = env.step([ACTION_DO_NOTHING])
done, info = dones[0], infos[0]
total_requests_active.append(info['total_requests_active'])
return total_requests_active
plt.xlabel('time')
plt.ylabel('total active requests')
plt.title('Total requests active in our cluster')
plt.plot(get_total_requests_active_over_single_run())
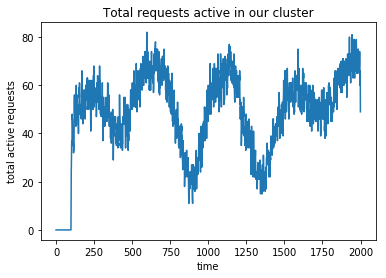
With those parameters, our cluster gets up to just above 80 requests being processed by the system at peak traffic, and just below 20 during the lowest points. With a server capacity of 10, our 20 server maximum is way more than we will ever need. We expect that our best agents will scale the number of servers between 3 and 9. Because this is a random process, you can also run this multiple times and average them together to get a better sample.
Now that we know what to expect, it’s time to pick our reward function.
Choosing a reward function
As usual, we’ll start with something simple. We know that we don’t like errors, so let’s punish the agent with a negative reward for each error.
def reward_fn(errors, last_errors, cluster):
return (last_errors - errors) / MAX_REQUESTS_PER_TIMESTEP
We also normalize the reward so it’s between -1 and 0. Before you run this (or scroll down), think about what you would do in your agents’ shoes. Put on your best lawyer hat (or whatever profession you think is good at finding loopholes).
env = make_multi_process_env(reward_fn = reward_fn)
model = PPO2(MlpPolicy, env, verbose=0)
model.learn(total_timesteps=1000000)
display_strategy(make_single_env(reward_fn, wrap=True))
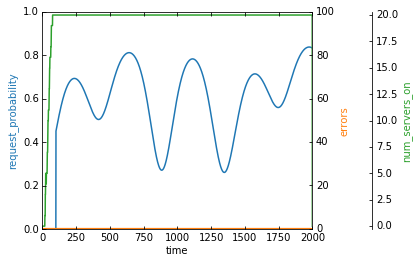
We got no errors, but not exactly in the way we wanted. This was maybe obvious, but our agent learns to scale up quickly to the maximum number of servers and then it keeps them on forever. We told our agent that the only thing we care about is that errors don’t happen, so naturally, more servers are always going to be better than less.
Ok, that was a silly mistake. Let’s tell the agent that we still want it to minimize errors, but once there are 0 errors, it should switch to minimizing the number of servers. To do this, we will model our reward function similarly to how you compare tuples. If there are errors, we’ll return a negative reward based on how many errors there are, but if there are 0 errors, we’ll return a reward based on how many servers are on.
def reward_fn(errors, last_errors, cluster):
error_reward = (last_errors - errors) / MAX_REQUESTS_PER_TIMESTEP
if error_reward != 0:
return error_reward
else:
num_servers_on = sum([1.0 if server.is_on() else 0.0
for server in cluster.get_servers()])
server_reward = -num_servers_on / cluster.get_max_num_servers()
return server_reward
Once again, after you read the code, think about what you expect the agent to learn and what you might do.
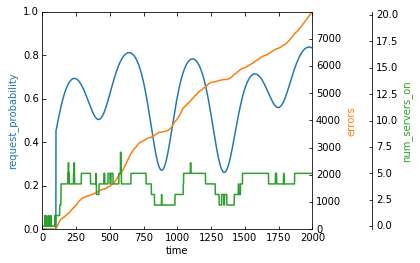
Here’s the same chart with the num_servers_on axis scaled down:
It looks like it’s trying to scale the clusters based on the rate of requests, but the error rate is climbing very fast. We also said that we need 8-9 servers for peak traffic, but our agent never goes above 6 servers.
It turns out that even though we thought about our reward function similarly to comparing tuples, our agent doesn’t know that. Our agent only sees the rewards that it receives. In this case, if there was only one new error, the agent gets a reward of -1 / MAX_REQUESTS_PER_TIMESTEP or -1 / 30. However, each server that is on contributes -1 / cluster.get_max_num_servers() or -1 / 20 to our reward.
Since we know we need a decent number of servers to handle the requests, it’s actually advantageous for our agent to never get to 0 errors. Once our agent gets to 0 errors, it gets hit with the large penalty for each server that’s on. Our reward function is actually forcing our agent to try and get as close to 1 new error every timestep (without going over), which is pretty hard in this environment.
Alright, third times the charm. What if we took the cost of running servers, and scaled it down so that the cost of all servers being on is less than the cost of a single error. This way, the agent should learn that errors are the worst thing that can happen, but after all the errors are gone, fewer servers are better than more servers.
def reward_fn(errors, last_errors, cluster):
error_reward = (last_errors - errors) / MAX_REQUESTS_PER_TIMESTEP
num_servers_on = sum([1.0 if server.on else 0.0
for server in cluster.get_servers()])
server_reward = -num_servers_on / cluster.get_max_num_servers()
server_reward = server_reward / (10 * MAX_REQUESTS_PER_TIMESTEP)
return error_reward + server_reward
The rule of three says this should probably work, but what do you think?
env = make_multi_process_env(reward_fn = reward_fn)
model = PPO2(MlpPolicy, env, verbose=0)
model.learn(total_timesteps=5000000) # train for a little longer
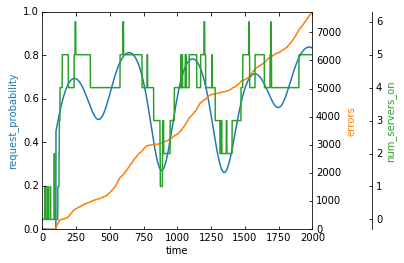
display_strategy(make_single_env(reward_fn, wrap=True))
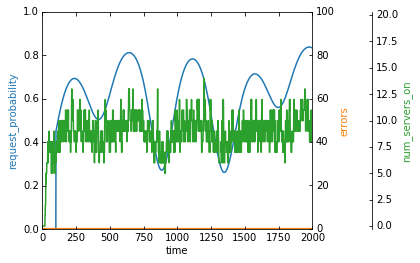
Phew, ok, we finally did it. Our errors are low and our agent is scaling the number of servers between 5 and 13 servers. These are both greater than our ideal 3 and 9 servers from our “capacity plan”, but that’s likely due to both the noise the agent has to deal with and the fact that servers take time to start up/shut down.
We’ve now written a reward function which more appropriately matches what human intuition would tell us to do in this case. It’s also important to point out that there are so many other reward functions that you can try. You could:
- Penalize the agent only for unused capacity on each server
- Weight how much you penalize errors by the request rate (e.g. errors are more acceptable when the rate is high)
However, this is a blog about unnecessary AI, so let’s overengineer this. I have no idea what the best reward function is. It might actually be the case that trying to get to 0 errors costs 10 times as much as allowing an occasional error.
I do know that ultimately what I actually care about is money. Errors are bad because errors are a missed opportunity for revenue (that request could have been a user trying to add something to a shopping cart, for example). Successful requests are good because they are opportunities for users to give us their money. So, what if we redo our reward function such that we maximize our profits?
Becoming rich thanks to machine learning
Let’s assume that we are an online store. We’ll also assume that each request is a new user on our site, and that means each request has a customer acquisition cost associated with it. Each server that’s on will also have a cost associated with it.
As for making money, let’s assume that each user has some probability of buying from us, and if they do, we’ll sample from another lognormal distribution to figure out how much money they spent.
While we’re at it, we might as well have our agent figure out our marketing budget too. The parameter that controls our approximate request volume is MAX_REQUESTS_PER_TIMESTEP. If we allow our agent to increase it, the number of requests will go up. Since each request has a customer acquisition cost associated with it, increasing MAX_REQUESTS_PER_TIMESTEP is essentially increasing our marketing budget, and decreasing it is the opposite.
We’ll allow the agent to scale the max requests per timestep up to just under twice what we used in testing, and we’ll increase the maximum number of servers in our cluster to compensate.
I’m going to make up the numbers for customer acquisition cost and all that, but in theory, this should tell us both how much we should spend on marketing and the optimal autoscaling strategy to maximize our profits!
Here is our reward function:
CUSTOMER_ACQUISITION_COST = 2.00
CUSTOMER_CONVERSION_PROBABILITY = 0.01
SERVER_COST_PER_TIMESTEP = 0.02
MAX_REWARD_VALUE = 100 # used for normalizing, doesn't need to be exact
# Need new parameter num_requests
def reward_fn(errors, last_errors, cluster, num_requests):
new_errors = errors - last_errors
successful_requests = num_requests - new_errors
request_cost = get_request_cost(num_requests)
money_made = get_money_made(successful_requests)
server_cost = get_server_cost(cluster)
return (money_made - request_cost - server_cost) / MAX_REWARD_VALUE
def get_request_cost(num_requests):
return CUSTOMER_ACQUISITION_COST * num_requests
def get_money_made(successful_requests):
money_made = 0.0
for _ in range(successful_requests):
if flip_coin(CUSTOMER_CONVERSION_PROBABILITY):
money_made += get_simulated_purchase_amount()
return money_made
def get_server_cost(cluster):
num_servers_on = sum([1.0 if server.is_on() else 0.0
for server in cluster.get_servers()])
return num_servers_on * SERVER_COST_PER_TIMESTEP
def get_simulated_purchase_amount():
orders = np.random.lognormal(0, 0.5, (1, )) * 20 + 2
return orders[0]
We also need to modify our environment to pass in num_requests but I’m going to omit that because it’s pretty trivial. Now let’s talk about how our environment needs to change to find the optimal value of MAX_REQUESTS_PER_TIMESTEP.
Determining our optimal marketing spend
If we want to have our agent control the number of requests, we’d need to somehow add it to the environment as an action. We could try having the agents’ actions include actions for controlling our marketing spend, but I think there’s an easier way to model this. MAX_REQUESTS_PER_TIMESTEP is just a parameter to our system, so we can use hyperparameter tuning to select the best value. We’ll be using the python library hyperopt to do this.
Hyperopt is a library that lets you define all the possible inputs to a black-box function, and it will search over your possible inputs in order to minimize (or maximize) the output of your function. The important point here is that it makes no assumptions about your function. Here’s an example of using hyperopt to minimize the function x**2 over all doubles between -10 and 10 (taken from hyperopts documentation here)
from hyperopt import fmin, tpe, hp
best = fmin(fn=lambda x: x ** 2,
space=hp.uniform('x', -10, 10),
algo=tpe.suggest,
max_evals=100)
print(best)
In our case, the black-box function is “how much money do we make when we try a specific value of MAX_REQUESTS_PER_TIMESTAMP assuming our agent optimally scales our cluster for that volume of requests?“. An obvious problem is that waiting for our agent to learn an optimal autoscaling policy is going to take a while, and we have to pay that cost every time we want to test out a different value.
To save some time, we’ll ask our agent to train for an amount of time that isn’t too long but will still give us good enough signal about how much money we are going to make. After some trial and error, I choose 100k timesteps.
Let’s first redefine our environment creation functions to take in the parameter:
MAX_NUM_SERVERS = 30
SERVER_CAPACITY = 10
MIN_MAX_REQUESTS_PER_TIMESTEP = 0
MAX_MAX_REQUESTS_PER_TIMESTEP = 50
FRAME_STACK_SIZE = 8
NUM_PROCESSES = 8
def make_single_env(reward_fn, max_requests_per_timestep, rank=0, wrap = False):
...
def make_multi_process_env(reward_fn, max_requests_per_timestep):
...
And then we can create our own function that hyperopt will minimize (called the objective function):
def objective(max_requests_per_timestep):
max_requests_per_timestep = int(max_requests_per_timestep)
env = make_multi_process_env(reward_fn = reward_fn,
max_requests_per_timestep = max_requests_per_timestep)
model = PPO2(MlpPolicy, env, verbose=0)
model.learn(total_timesteps=100000)
env.close()
env = make_single_env(reward_fn = reward_fn,
max_requests_per_timestep = max_requests_per_timestep,
wrap=True)
# Average across a few runs to get a better estimate
return sum([get_overall_reward(env, model) for _ in range(5)]) / 5
def get_overall_reward(env, model):
obs = env.reset()
overall_reward = 0
while True:
action, _states = model.predict(obs)
obs, rewards, dones, infos = env.step(action)
overall_reward += rewards[0]
if dones[0]:
break
# Hyperopt only exposes a min function
# Since we want to maximize our reward, we will negative this value before returning it
return -overall_reward / MAX_TIME
We’ll then ask hyperopt to minimize our objective function (aka find our optimal max_requests_per_timestep) and finally we’ll train an agent with the best value that it finds.
from hyperopt import hp, fmin, tpe, space_eval
space = hp.quniform('requests_per_timestep',
MIN_MAX_REQUESTS_PER_TIMESTEP,
MAX_MAX_REQUESTS_PER_TIMESTEP,
1)
best = fmin(objective, space, algo=tpe.suggest, max_evals=60)
max_requests_per_timestep = space_eval(space, best)
env = make_multi_process_env(reward_fn=reward_fn,
max_requests_per_timestep=max_requests_per_timestep)
model = PPO2(MlpPolicy, env, verbose=0)
model.learn(total_timesteps=3000000)
display_strategy(make_single_env(reward_fn=reward_fn,
max_requests_per_timestep=max_requests_per_timestep,
wrap=True))
Sit back and wait since this’ll take a while to train.

Us, eagerly waiting to collect our profits
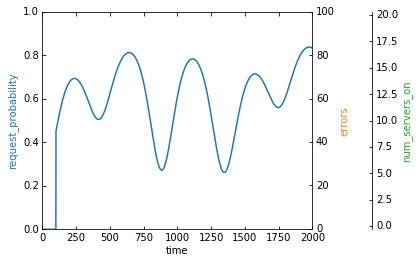
Well... this is depressing. Why are all our servers off? And where are all the errors? Let’s check what max_requests_per_timestep is.
> print(best)
{'requests_per_timestep': 0.0}
The optimal amount to spend on marketing is nothing. Our customer acquisition cost is too high relative to their value in our environment, so our system decided to stop acquiring customers. Similarly, if we aren’t acquiring customers, there’s no point in turning servers on, so our agent decided that it’s best if we close up shop.
I’ll admit that I fudged the numbers a bit for this outcome, and this example also doesn’t take into account things like long-term customer value or the fact that our servers are ridiculously expensive compared to their capacity. However, the point still stands, if you try and maximize your profit, and your numbers don’t look good, your agent can decide to shut your business down for you.
Conclusion
I don’t want the message to be that you shouldn’t ever do this. You could definitely make an A/B testing framework that optimizes profits, for example. The overall point is just to be careful. If we made our environment more realistic and were more careful with what we asked our agent to do, we could’ve ended up with our agent helping scale our business, instead of quietly telling us to move on.
If you have interesting stories about unfortunate reward functions, post them down below!