There are times when you want to sit down and think hard about a problem to figure out an optimal solution... then there are times when you realize it’s 2019 and bots should be solving all our problems by now. In this post, I will show you how to train a bot to learn whatever you want.
Ok, ok, so not any problem. We aren’t curing anyone’s depression today. We can only solve problems that we can describe and model. What we are about to do is called Reinforcement Learning, and here’s how Wikipedia describes it:
Reinforcement learning (RL) is an area of machine learning concerned with how software agents ought to take actions in an environment so as to maximize some notion of cumulative reward.
It differs from supervised learning in that labelled input/output pairs need not be presented, and sub-optimal actions need not be explicitly corrected. Instead the focus is finding a balance between exploration (of uncharted territory) and exploitation (of current knowledge).
The definition talks about an environment, but what is an environment in RL? It’s really anything that an agent (or bot) can interact with. In the gif below, my dog is an agent interacting with an environment I created. If he hits my hand, the environment rewards him with a treat, and if he doesn’t, he gets no reward. Normal people will call this dog training, but you can now call it reinforcement learning in a complex, real-world environment.

Reinforcement learning with an adorable agent. Rewards were given later.
The last sentence in the definition is important. We are teaching an agent to interact with an environment and each interaction has some reward associated with it. For complex environments, our agent needs to understand actions that produce positive and negative rewards, but it also needs to learn how and when to try new actions. My dog didn’t always know that trick, he needed to try that action a few times and notice that each time produced a reward. There are posts like this where a team teaches an agent to be curious to get it to complete tasks in a 3D environment, which is just really cool.
But let’s not get ahead of ourselves, we will start small. Because this is a very active area of research, we get to benefit from a lot of smart people that have built a ton of useful utilities. In our case, we need a few things to get started:
- An environment for our agent to explore
- An agent capable of learning
Creating the environment
When I defined an environment before I said it was “anything than an agent can interact with”, but that definition, while technically correct, isn’t all that helpful in practice. If we want to use complicated agents that other people have created, we must agree on some common interface for environments. This is where OpenAI gym environments come in.
OpenAI environments are just a straightforward interface for an arbitrary RL environment. They have even implemented a bunch of Atari/NES games as OpenAI environments so you can train your agents on complex scenarios.
To define these environments, you need to define the following things:
- Observation space: What your agent sees
- Action space: What your agent can do
- Reward function: What you encourage/discourage your agent from doing
For our first environment, we will play a simple game. We’ll pick a random number from the set of integers {0, 1, 2}, show our agent this number, and then ask our agent to tell us the number it saw.
The observation space is the set of integers {0, 1, 2}. The action is the guess that the agent makes, so the action space is also the set of integers {0, 1, 2}. We will reward our bot with 1 “point” when it is right, and nothing when it is wrong. This game is really simple, so if our agent can’t solve this, we know there’s something wrong.
The following is that game in an OpenAI environment (gym.Env in code)
from gym import spaces
import gym
import random
import numpy as np
class GuessingGameEnv(gym.Env):
def __init__(self, num_choices):
self.num_choices = num_choices
self.action_space = spaces.Discrete(num_choices)
self.observation_space = spaces.Discrete(num_choices)
self.reset()
def reset(self):
self.goal = random.randint(0, self.num_choices - 1)
self.guesses = [] # Used for rendering
self.done = False
return self._get_observation()
def step(self, action):
if self.done:
raise Exception('Game has already ended')
reward = self._take_action_get_reward(action)
obs = self._get_observation()
return obs, reward, self.done, {}
def _take_action_get_reward(self, action):
self.guesses.append(action)
if action == self.goal:
# Game ends when the agent guesses the goal
self.done = True
return 1.0
else:
return 0.0
def render(self, mode='human', close=False):
print('Goal is', self.goal, '\tGuesses so far are', self.guesses)
def _get_observation(self):
return self.goal
def seed(self, seed):
random.seed(seed)
Some important notes:
- A discrete space for num_choices is the set of integers less than num_choices, or {0, 1, 2} if num_choices is 3.
- The step function returns the next observation, reward, done, and any extra information you want to return after taking the action. In our case, we don’t have any extra information.
- Reset needs to return the initial observation.
- For another starter example which includes registering the environment (unnecessary for our case, but good practice), check out this repo.
Let’s quickly test it by making a bot that randomly guesses.
def play_game(env, render = False):
obs = env.reset()
done = False
total_attempts = 0
while not done:
action = env.action_space.sample()
obs, rewards, done, info = env.step(action)
total_attempts += 1
if render:
env.render()
return total_attempts
Note that env.action_space.sample() gets any random valid action. And when we run it we get:
> env = GuessingGameEnv(3)
> play_game(env, render = True)
Goal is 1 Guesses so far are [0]
Goal is 1 Guesses so far are [0, 2]
Goal is 1 Guesses so far are [0, 2, 0]
Goal is 1 Guesses so far are [0, 2, 0, 1]
4
So the goal was 1 and our bot tried 0, 2, 0, and finally 1. Thankfully, this isn’t the type of bot that’s going to be driving your car. Now that everything seems to work there, all we need is an agent to play our game. We could build an agent that can beat this game every time (there actually is one below, but trust me, it’s boring), but that wouldn’t be fitting with the theme of unnecessary AI. Instead, let’s use a powerful RL algorithm called Proximal Policy Optimization (PPO).
Creating the bot/agent
If you want a really thorough description of PPO, this video is my personal favorite. However, for our purposes, all you need to know is that it does a good job of learning which actions to take to maximize the overall reward from an environment. OpenAI has an implementation in their baselines repo but I’m going to use the implementation in this stable-baselines repo instead. Stable-baselines is a fork of baselines that I’ve found to be easier to use.
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines import PPO2
from stable_baselines.common.policies import MlpPolicy
env = GuessingGameEnv(3)
env = DummyVecEnv([lambda: env])
model = PPO2(MlpPolicy, env, verbose=0)
model.learn(total_timesteps=1000)
Yeah, stable-baselines is great. All we need to do is wrap our environment in their DummyVecEnv, construct a model, and ask it to learn.
But what is that MlpPolicy that the model takes in? To answer that we first need to talk about policies. A policy is just a function that maps your observation space to your action space. It takes in an arbitrary observation and tells you the probabilities that you should take any of the actions. As an example, the following are optimal and random policies for our GuessingGameEnv(3)
def optimal_policy(obs):
action_probabilities = [0.0, 0.0, 0.0]
action_probabilities[obs] = 1.0
return action_probabilities
def random_policy(obs):
return [1/3, 1/3, 1/3]
Our agent’s job is to modify its policy to increase the rewards it receives from the environment. The above policies aren’t really easily modifiable in any algorithmic way. The policies we will use, however, are neural networks that can modify their internals to better approximate any function. In this case, we will teach it to approximate the function “given a random number from {0, 1, 2}, what is the probability that I should pick 0, 1, or 2 to maximize my reward in this game”? The better our function does, the more it’s input and output pairs will resemble the optimal_policy function above.
There are a lot of preexisting policies to choose from or you can implement your own. The MlpPolicy uses a multilayer perceptron neural network, whereas a CnnPolicy uses a convolutional neural network. You can read more about them, but the gist is you’ll want to use a CnnPolicy when your observation space has some spatial information (images, videos, music, etc) and an MlpPolicy when you have tabular data.
I should point out once again that this is extreme overkill for the problem we are solving, but the point is to show a proof of concept. There are a lot of parameters that we could tune if we want to, but we’re playing guess that number and telling our bot which number to guess so it’ll probably work out.
Let’s now produce a histogram of how the bot performs over 1000 games. We need to redo our play_game method to use the model’s prediction instead of a random prediction and I removed the render code for brevity.
import matplotlib.pyplot as plt
def play_game(model, env):
obs = env.reset()
done = False
total_attempts = 0
while not done:
action, _states = model.predict(obs)
obs, rewards, done, info = env.step(action)
total_attempts += 1
return total_attempts
plt.hist([play_game(model, env) for _ in range(1000)], bins=range(1, 10))
plt.xlabel('How many tries it took our bot to guess correctly')
plt.ylabel('Frequency')
plt.show()
Agent trained for 1k timesteps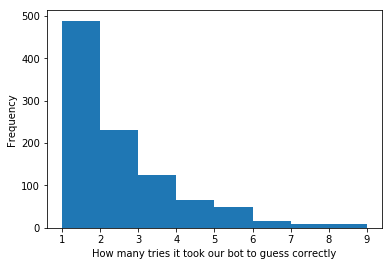
To put this in perspective, a random bot will get it right on the first try 1 out of every 3 times, whereas our bot gets it right on the first try about 1 out of every 2 times. We are officially better than randomly guessing, but since that’s not saying much let’s keep training and recheck the histogram.
model.learn(total_timesteps=30000)
plt.hist([play_game(model, env) for _ in range(1000)], bins=range(1, 10))
plt.xlabel('How many tries it took our bot to guess correctly')
plt.ylabel('Frequency')
plt.show()
Agent trained for 31k timesteps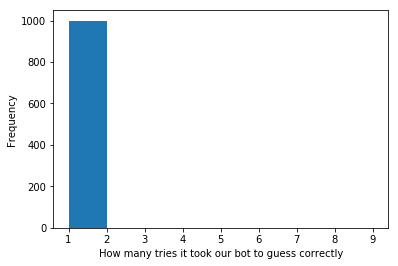
And this is hopefully what you expected. The bot learns that we are providing the answer and copies it. In a future post, we can dig in a lot more into the details of PPO and different RL algorithms, but for now, hopefully you understand how powerful this example is. With very little code we trained a neural network to mimic us, and while that itself might not be the most exciting, what if you tried:
- Reading live stock market data and reward your bot based on how much money it made/lost
- Using Minecraft as an environment
- Making an environment where multiple agents learn to communicate securely with an adversary listening
If you do find or implement other ideas, please send them to me! I’m always interested in hearing about cool environments.